How It Works
The Complete TOE-Share Walkthrough
From your first paste to a published, peer-evaluated submission — with every tool and option explained along the way.
Step 1: Choose Your Path
The first thing you decide is what you're submitting and whose work it is. This shapes your entire experience.
Framework
The big picture — your unified theory, mathematical structure, and prediction landscape. Frameworks are reviewed on 7 dimensions including Evidence Strength.
- ◆ Defines foundational assumptions and axioms
- ◆ Grows stronger as you link supporting papers
- ◆ Gets composite scoring across the full evidence package
Paper
A focused contribution — a derivation, a test of a prediction, a data analysis. Papers are reviewed on 6 dimensions.
- ◇ Tests or develops specific claims
- ◇ Can be linked to one or more frameworks
- ◇ Strengthens a framework's evidence base when linked
Is this your work or someone else's?
My original work
- ✓Full editing access — revise and iterate anytime
- ✓Challenge AI scores you disagree with
- ✓Declare foundational assumptions for paradigm-neutral review
- ✓Publish when approved — your name, your credit
Someone else's work
- ✓Submit as a reference — the original author retains credit
- ✓Link it as supporting evidence for your framework
- ✓Get an independent AI review of the work
- ✓Import directly from arXiv or Zenodo links
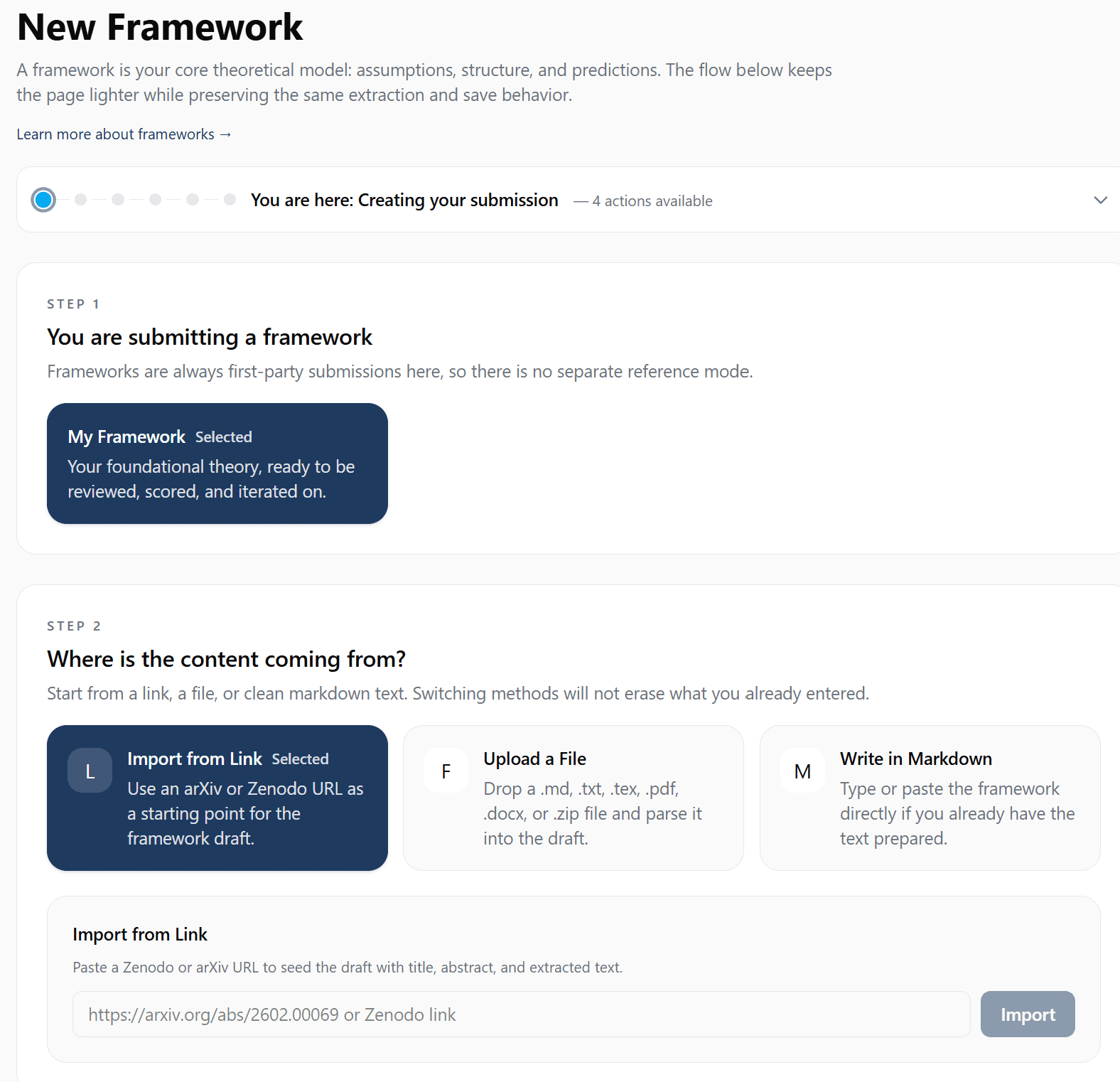
Step 2: Build Your Submission
Add Your Content
You have multiple ways to get your content into TOE-Share:
- Write directly in the Markdown editor with live preview
- Upload files — .md, .txt, .tex, .pdf, .docx, or a .zip bundle with figures
- Import a link from arXiv or Zenodo — content is pulled automatically
The screenshot above shows the full new-submission flow — the three import options (Link, File, Markdown) are right below the path selector.
Declare Your Paradigm (Optional but Powerful)
If your work departs from mainstream physics — alternative cosmology, modified gravity, non-standard QM interpretation — tell the AI upfront.
Foundational Assumptions
Use this field to declare what your framework assumes. The AI reviewers will evaluate your internal consistency, math, and predictions within your stated premises rather than penalizing you for not matching the standard model.
Example: “This framework assumes a scale-dependent coupling constant rather than fixed constants. All predictions should be evaluated within this premise.”
You can always add or edit assumptions later. And if the AI identifies a paradigm departure during a challenge, it can suggest adding it as an assumption automatically.
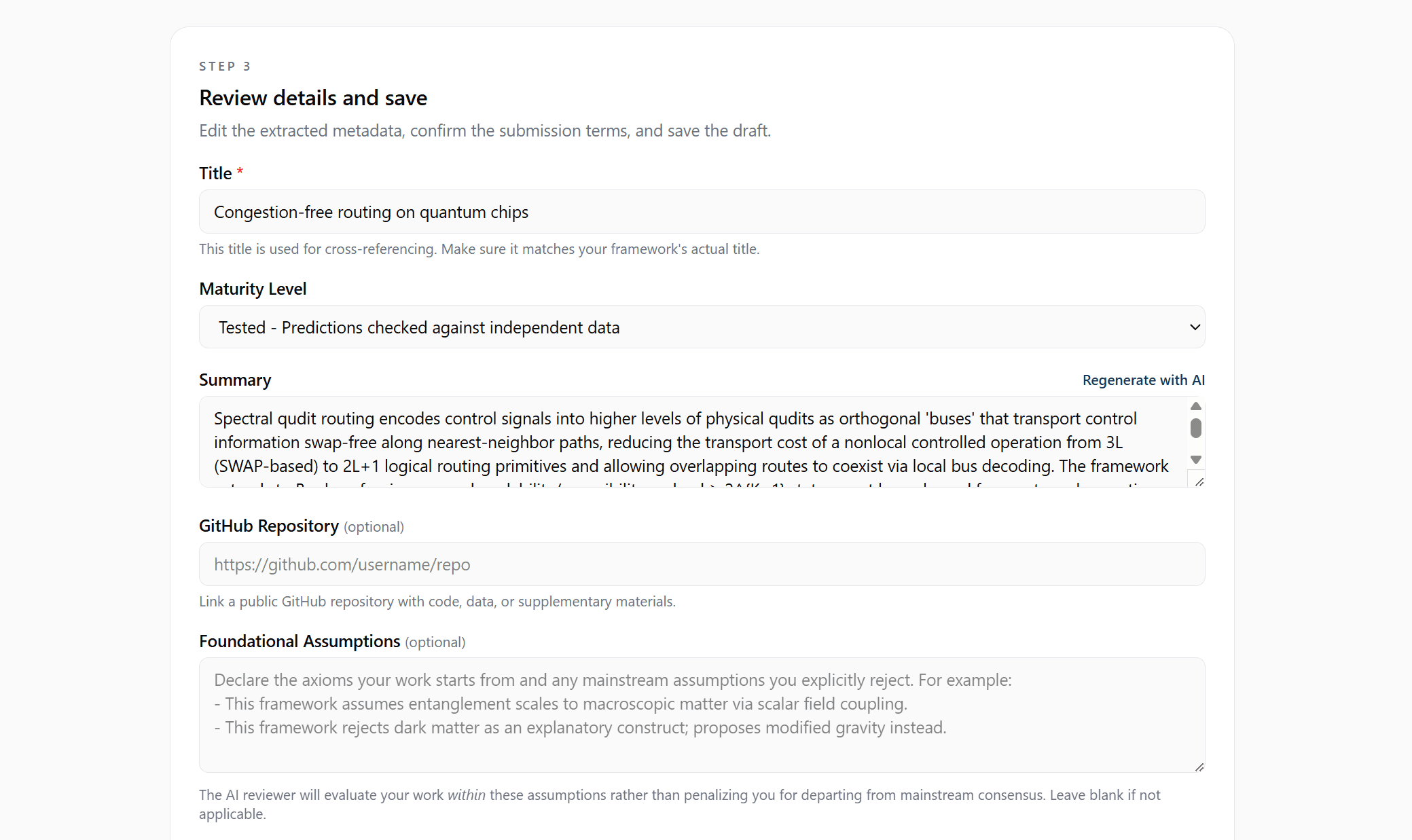
Let AI Extract Your Metadata
Click “Analyze with AI” and the system will read your content and suggest:
You review every suggestion and accept or override. This happens before your first save — no need to create a draft first.
The extraction results appear inline — review each suggestion and accept, edit, or discard before saving.
Link Supporting Papers (Frameworks)
If you're submitting a framework, attach papers that back it up. Each link includes a relationship type:
Linked papers are reviewed together with your framework as a composite. More evidence = stronger scores. You can keep adding papers after review.
Step 3: AI Review
When you click “Submit for AI Review,” a team of specialist AI agents evaluates your work in parallel.
Behind the Scenes
Math Specialist
Validates equations, checks derivations, tests calculations
Sources Specialist
Checks references, validates citations, evaluates evidence
Science Specialist
Evaluates testability, prediction clarity, novelty
Each specialist can run across multiple AI labs (Anthropic, OpenAI, Google, xAI) for cross-validation. The model lineup is configurable and updated as better models become available.
Synthesis Agent
Reads all specialist reports, resolves disagreements, and produces the unified assessment
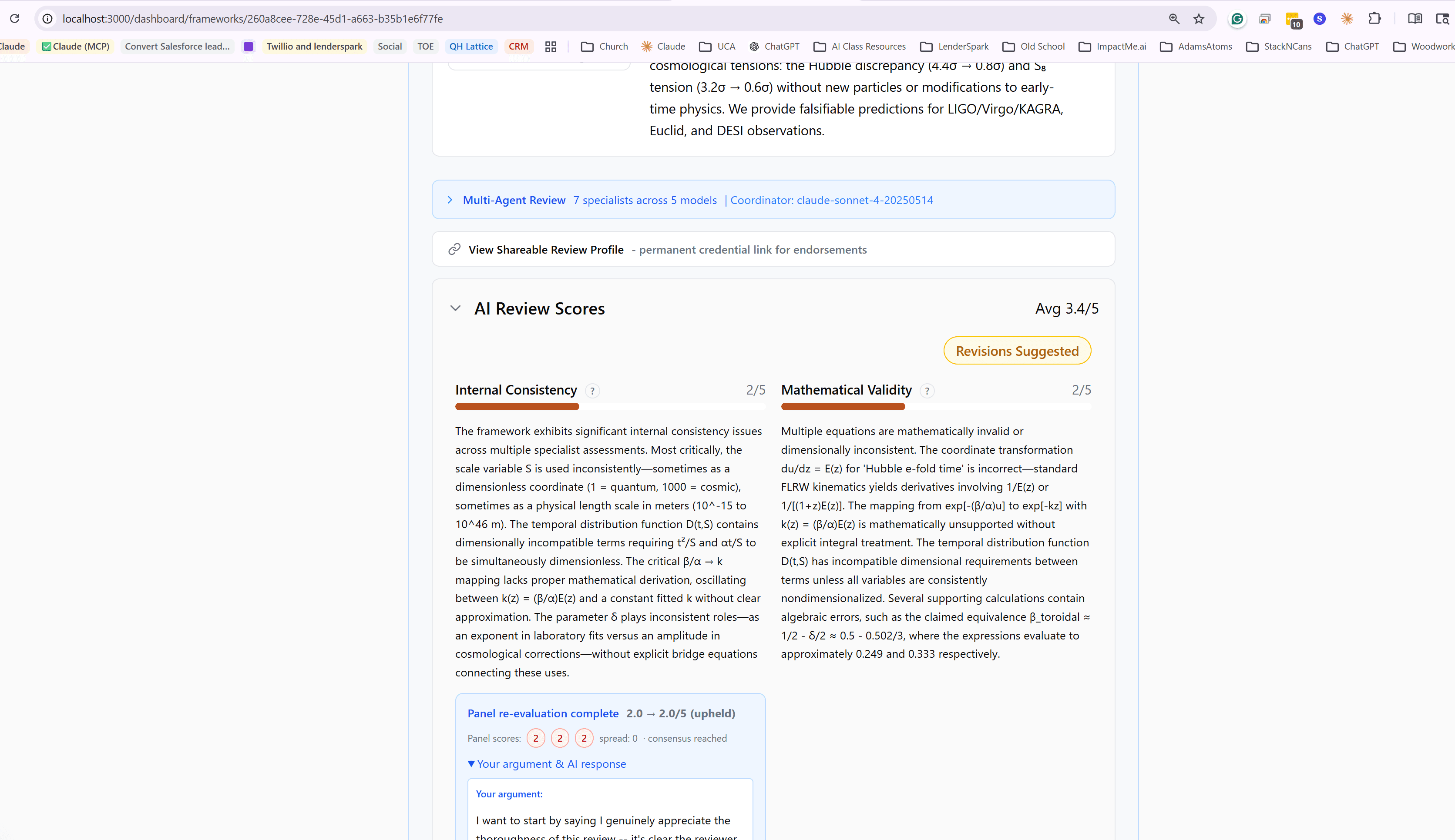
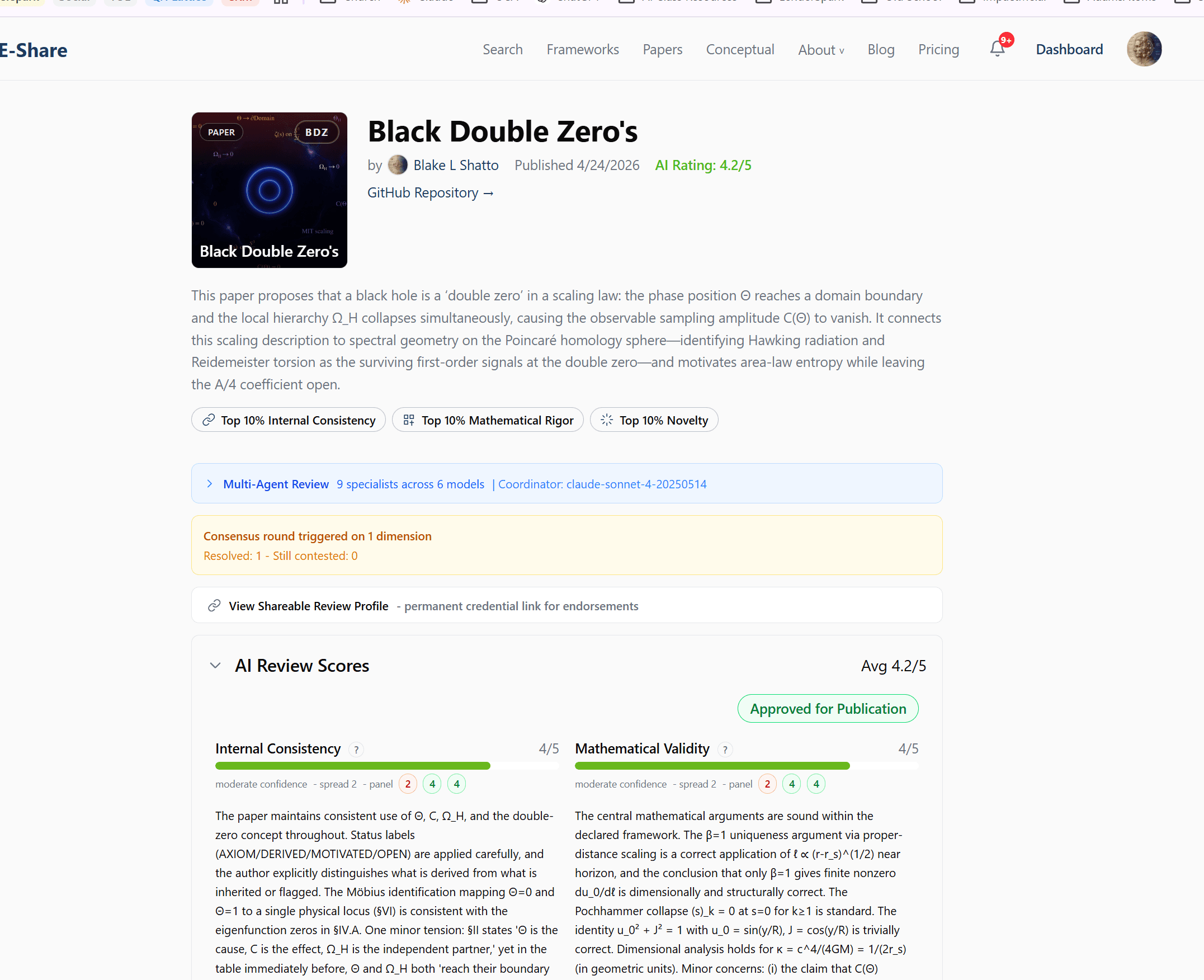
The 7 Review Dimensions
Each scored 1–5 with detailed explanations, strengths, and specific improvement suggestions.
Internal Consistency
Math SpecialistDo assumptions, definitions, and conclusions cohere?
Mathematical Validity
Math SpecialistAre equations correct, derivations sound, notation defined?
Falsifiability
Science SpecialistAre there specific, testable predictions with clear conditions?
Clarity
Science SpecialistCan a physicist in a related field follow the reasoning?
Novelty
Science SpecialistDoes this offer something genuinely new?
Completeness
Source SpecialistAre gaps, limitations, and edge cases addressed?
Evidence Strength
Source SpecialistHow well do linked papers back the claims? (Frameworks only)
Approved → Can Publish
- ✓Every dimension scores at least 2/5
- ✓Overall average of 3/5 or higher
Conceptual Track
- →Below the publication threshold
- →Receives a detailed improvement roadmap
- →Can iterate and resubmit at any time
There are no dead ends. Every submission gets a path forward.
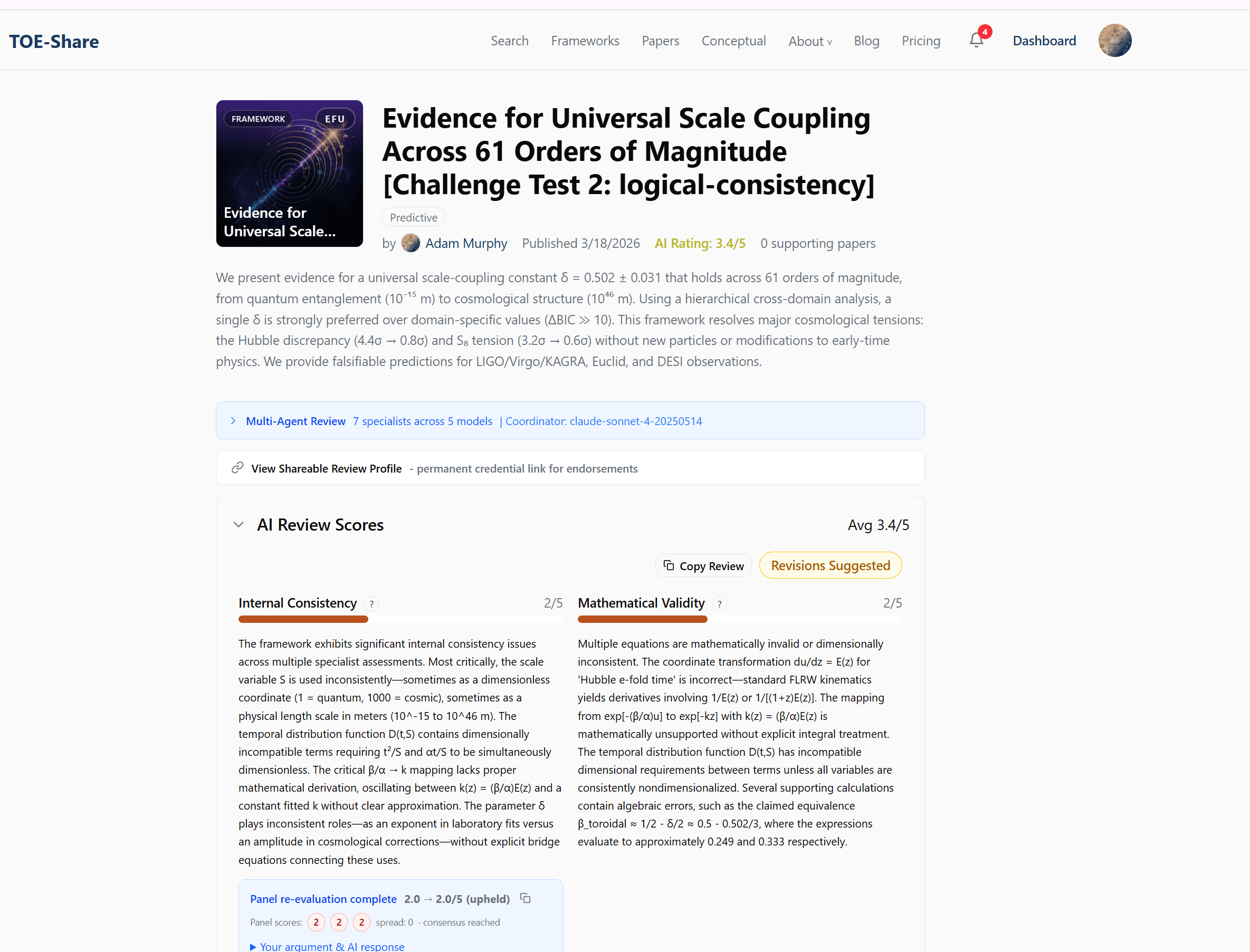
Step 4: You Got Your Scores — Now What?
This is where most people stop, but it's actually where the real work begins. You have multiple plays available after every review. The right combination can dramatically improve your scores.
Challenge Your Scores
Disagree with a score? Write a counter-argument and a panel of 2–4 independent AI judges re-evaluates it. You get one challenge per dimension per review cycle.
Link Supporting Papers
Each paper you link strengthens the evidence base. On your next re-review, the AI evaluates the framework and all linked papers together as a composite.
Relationship types: supports, extends, applies, challenges, constrains.
Add or Edit Assumptions
Declare paradigm departures so the AI evaluates within your framework's premises. If your work assumes modified gravity, say so — the AI adjusts its evaluation accordingly.
Edit & Re-run Review
Revise your content based on the feedback, then submit for a fresh full review. New snapshot, new scores, new review history entry. This also resets your challenge opportunities.
Ask the AI
Open the AI chat panel and ask questions about your scores, request clarification on specific feedback, or explore improvement strategies. The AI has your full content and review loaded as context.
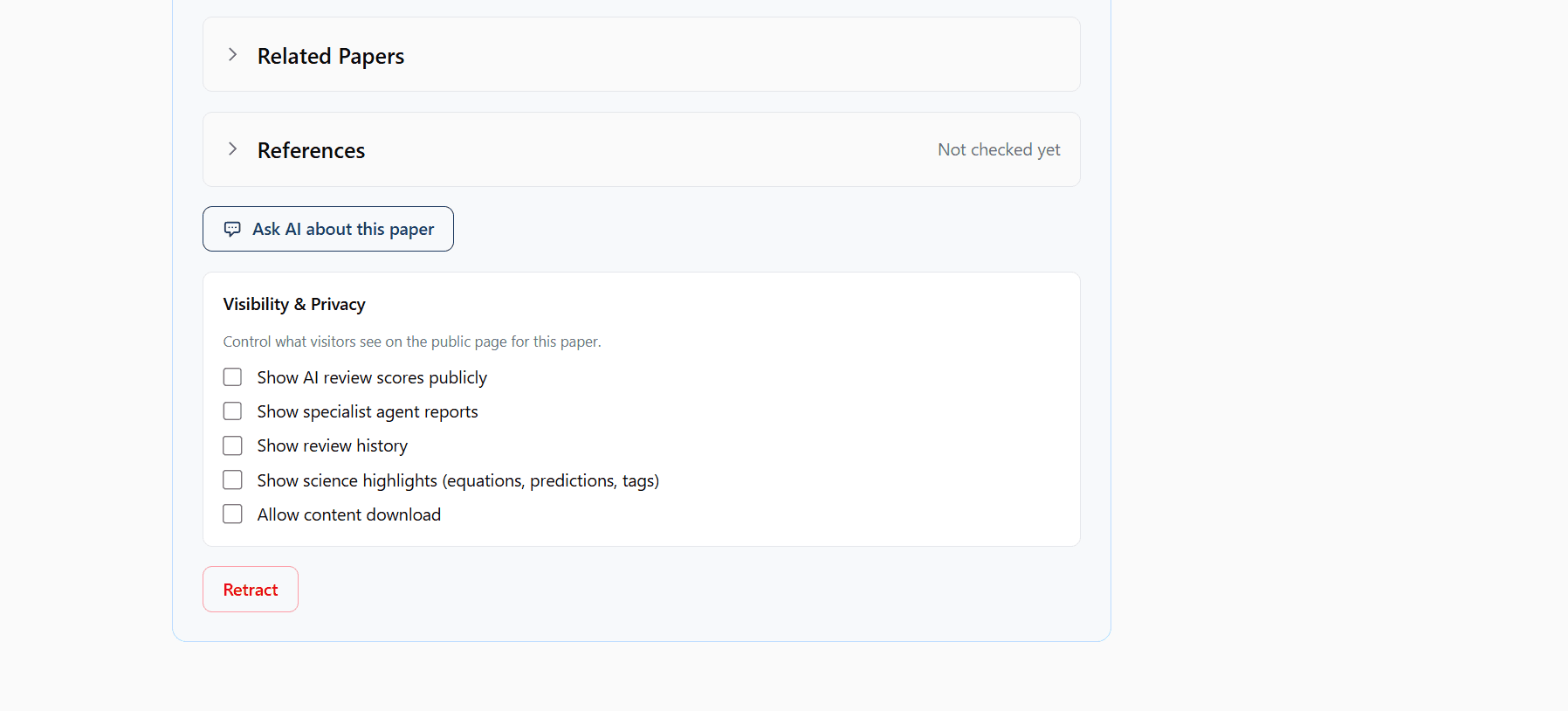
Control Visibility
Toggle what the public sees: scores, specialist reports, review history, equations, downloads. Hide scores while you improve, reveal them when you're satisfied.
The Winning Combination
The most effective strategy isn't just one play — it's a sequence:
Fix what you can. Read the feedback, revise your content, add supporting papers, tighten your math.
Re-run review. Get fresh scores that reflect your improvements. This also resets your challenge opportunities.
Challenge the remaining scores you still disagree with. Now you're challenging with a stronger submission behind you.
Deep Dive: Challenging Your Scores
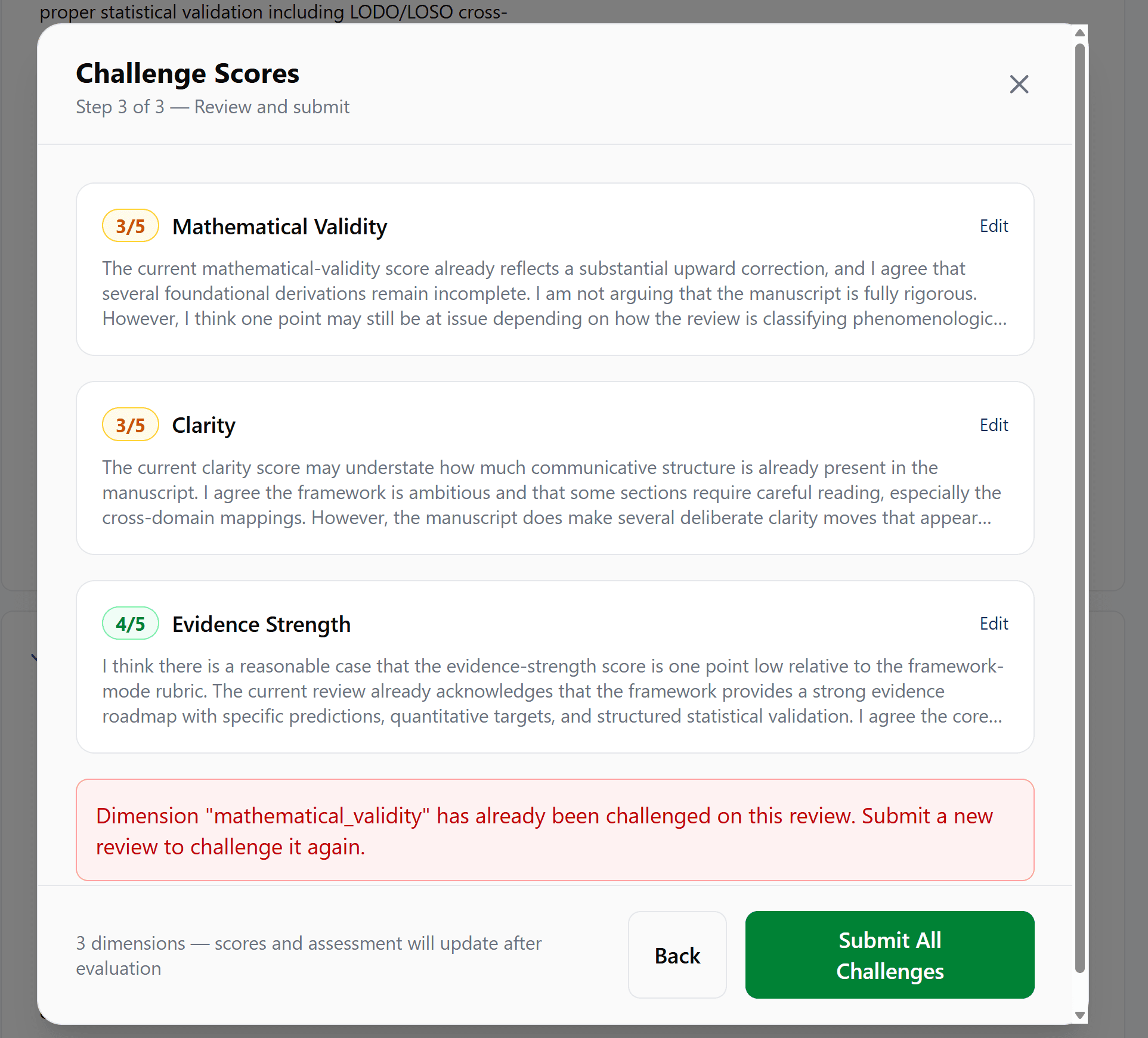
The challenge system is your most powerful tool. Here's exactly how it works.
Select dimensions
Pick which scores to challenge. You can batch up to 4 dimensions at once. Dimensions already at 5/5 can't be selected.
Write your case
For each dimension, explain why the score should change. Minimum 20 characters. Be specific — point to what the AI missed, provide context it didn't have, or explain why your approach is valid.
Panel evaluates
2–4 independent AI judges review your counter-argument against the original review. Each judge scores independently, then they cross-reference each other's reasoning.
Consensus reached
The panel reaches consensus. You see: per-judge scores, panel spread (how much they disagreed), consensus badge, and each judge's detailed reasoning.
What works
- ✓Specific math corrections with equations
- ✓Pointing to text the AI misread or missed
- ✓Explaining notation conventions the AI didn't pick up
- ✓Identifying a paradigm departure (may become an assumption)
What doesn't work
- ✗Flattery or emotional appeals
- ✗Name-dropping institutions or credentials
- ✗Circular reasoning (“it's consistent because the theory predicts it should be”)
- ✗Fabricated citations or results
When a challenge becomes an assumption
Sometimes the AI panel determines your challenge isn't a scoring dispute — it's a foundational premise of your theory. When this happens, the system suggests adding it to your declared assumptions. You can approve, edit, or reject the suggestion. If you approve, future reviews will evaluate your work within that premise automatically.
Step 5: Going Public
Publishing
Once your work is approved (meets the score threshold), click “Publish to TOE-Share.” Your work becomes visible to the entire community.
Integrity check: if you edited your content after the last review, the system requires a fresh review before publishing. This ensures your published scores always match the published content.
What the Community Sees
Once published, visitors can see your full content, AI scores, specialist reports, review history, linked papers, key equations, and predictions. But you control what's visible:
Each toggle lets you show or hide that section on your public page. Work in private until you're ready.
After Publishing
Publishing isn't the end — your work continues to evolve:
- ◆Keep linking papers — evidence builds over time
- ◆Edit & re-review — creates a new version with updated scores
- ◆Challenge scores — still available on published work
- ◆Share your review profile — a consolidated trust credential URL for endorsers, collaborators, and journal editors
- ◆Retract — formal withdrawal if needed; content stays visible with a retraction notice

The Full Lifecycle at a Glance
Ready to Get Started?
Whether you have a fully developed theory or an early concept, TOE-Share gives you structured feedback and a transparent path from idea to published work.